Modulo di scrittura software e Gestione Dati¶
Questo modulo ha lo scopo di introdurvi alle basi della programmazione ed alla sua applicazione al campo scientifico.
Nel corso di questo modulo useremo due linguaggi di programmazione di alto livello, python e matlab.
Oltre a questi linguaggi ne esistono moltissimi altri, tutti appropriati all'uso:
- R
- Julia
- Mathematica
- Scala
- E tanti altri ancora
Vedremo anche nel corso delle lezioni vari concetti che vi torneranno utili qualsiasi sarà il linguaggio con cui deciderete di lavorare.
In particolare oggi inizieremo discutendo il controllo di versione.
Ma prima, che cosa sono i linguaggi di alto livello, e perché vale la pena usarli?
I linguaggi di programmazione ad alto livello¶
Il termine "linguaggio di alto livello" è una forma colloquiale, non definita in senso formale, ma sono presenti varie proprietà che li accumunano.
Lo scopo comune è rendere molto più semplice lo sviluppo di codice. Tutto il tempo che non passo a cercare di ricordare come inizializzare un puntatore, lo posso spendere a rendere le mie analisi più interessanti
- nascondono la gestione diretta delle risorse del computer (memoria, puntatori, etc...)
- forniscono una sintassi più intuitiva ed espressiva
- arrivano corredati di molte funzioni e strutture dati di uso comune
- rendono molto semplice installare librerie aggiuntive che ne espandono le funzionalità
vediamo un esempio che possa aiutare a capire che cosa intendo, usando il Python
import os
filenames = [filename for filename in os.listdir('.') if filename.endswith('.txt')]
for filename in filenames:
os.rename(filename, filename.replace('.txt', '.csv'))
Vedete che il codice, anche senza commenti, è chiaro e leggibile, ed esprimo dei concetti molto complicati in poche linee di codice
Correttezza, ripetibilità (e riproducibilità), auditing¶
Oggi come oggi chi fa ricerca deve per forza scrivere del codice.
Ci viene insegnato a scrivere codice ma non a prendercene cura.
Un modo di dire comune nel campo dello sviluppo è:
Scrivi il tuo codice come se la prossima persona a doversene occupare fosse uno psicopatico che sa dove abiti.
Considerando il numero di progetti che lo scienziato medio deve seguire al giorno d'oggi, lo psicopatico in questione potreste essere voi!
- CORRETTEZZA: essere sicuri che il vostro codice faccia esattamente quello che pensate; qualsiasi modifica facciate, volete essere certi di non aver introdotto errori. Nel caso avvenisse, volete poter tornare indietro.
- RIPETIBILITÀ - I: volete essere in grado di ripetere un'analisi ottenendo gli stessi risultati a distanza di tempi anche lunghi. Questo vuol dire tenere traccia di quali siano i requisiti del vostro software, di come si usa, su quali dati e con quali parametri.
- RIPETIBILITÀ - II: permettere a qualcun altro di fare lo stesso, possibilmente senza che voi siate li fisicamente presenti a spiegare passo per passo.
- RIPRODUCIBILITÀ: permettere ad altri di fare lo stesso, e di testare il vostro codice (ed in generale le vostre idee) sul altri dati ed altri casi rispetto a quelli da voi esaminati.
- AUDITING: mantenere la storia del progetto, per sapere cosa è stato fatto, quando e perché. Queste sia per mantenere la comprensione acquisita nel tempo che per permettere a dei revisori esterni di verificare quello che avete fatto.
Cosa è necessario per avere del codice salubre?
- controllo di versione
- documentazione
- procedure di test
- automazione delle procedure
- design sensato della pipeline di lavoro
Durante questo corso cercheremo non solo di insegnarvi la programmazione di alto livello, ma anche come gestire i vostri progetti in modo da limitare il numero di momenti di terrore, disperazione e sconforto che avreste altrimenti.
Se pensate che stia scherzando, immaginate le seguenti situazioni:
- la vostra simulazione ha girato per 36 ore, e fallisce all'ultimo step. Non sapete come recuperare, dovete ripartire da capo, senza essere sicuri di quale sia l'errore
- durante l'edit della vostra tesi cancellate un paragrafo (o una intera sezione) e non ve ne accorgete
- vi chiedono di modificare una figura per un articolo, ma il codice per generarla deve far girare di nuovo la famosa simulazione di 36 ore
- dovete dedicarvi agli esami per 6-7 mesi, quando è il momento di riprendere in mano il progetto non ricordate più cosa aveste sperimentato e cosa era ancora nella lista delle cose da fare
- il vostro progamma richiede una serie di step ben precisi per eseguire correttamente. Il gatto vi nasconde il foglietto dove li avete appuntati sotto il divano
- avete tenuto la documentazione del vostro progetto, ma nell'ultimo backup vi siete dimenticati di copiare l'ultima versione ed ora avete la documentazione ed il codice che non coincidono.
- fate una modifica al vostro codice, e vi rendete conto durante la presentazione al professore che un passaggio era sbagliato e vi da dei risultati assurdi
- prendete in mano il codice di qualcuno, e non avete la più pallida idea del perchè una linea di codice sia lì, ma non potete cambiarla perchè non capite se è essenziale per il codice.
Questi sono solo alcuni esempi, assolutamente visti capitare nella vita reale, fonti di stress facilmente evitabile.
Le procedure che vi insegneremo non possono ovviamente contrastare la sfortuna cieca, ma possono arginarne gli effetti nocivi ed evitare il disastro totale.
E sono tutte abbastanza semplici perché usarle non sia uno sforzo immane!
il concetto dietro questi esempi e questi strumenti è la corretta gestione dei metadata (dati a proposito dei dati).
Considerate un pezzo di programma come quello di prima. Il nome delle variabili è assolutamente arbitrario, e non influenza in nessun modo il risultato del programma, ma se cambiassi i nomi a caso il codice, seppure corretto, sarebbe incomprensibile, difficile da modificare e in poco tempo dimenticherei completamente il suo scopo d'essere.
Nel codice di solito si usano nomi coerenti e commenti, ma c'è molto altro di cui possiamo tenere traccia se ne siamo consci.
Controllo di versione distribuito e Code Source Management¶
Avete mai avuto diverse copie di un file, chiamate doc_v1, doc_v2 e così via?
Bene, quello è un controllo di versione manuale. Grazie al computer possiamo fare di meglio.
Possiamo tenere traccia di tutto quello che succede, tornare indietro ad un momento qualsiasi, vedere le differenze fra due versioni successive ed anche tenere "universi paralleli" di versioni alternative.
I programmi che permettono di farlo sono i Sistemi di Controllo di Versione.
Questi sono poi affiancati da sistemi di Management del Codice Sorgente, che oltre a tenere traccia della versione permettono anche di tracciare i bug e la documentazione.
Fossil è una semplice soluzione integrata che vi fornisce tutto questo in un unico pacchetto.
È già estremamente utile per lavorare da soli, e permette di usare lo stesso strumento per collaborare, coordinando il lavoro di varie persone che lavorano allo stesso progetto, online ed offline.
Le collaborazioni avvengono tramite un server centrale che fa da punto di scambio.
Potete anche ospitarlo su di un vostro computer, il server è lo stesso programma che avete già scaricato.
Ogni modifica che farete sarà automaticamente registrata sul server in automatico, e passata agli altri quando si collegheranno.
cit:
se vale la pena di essere fatto, vale la pena di essere messo sotto controllo di versione
si può scaricare dal suo sito web: Fossil-SCM.
È un programma free ed open source, cross-platform e contenuto in un unico file, quindi è molto facile da spostare in giro.
Il vostro repository è contenuto in un unico file, un database che contiene tutte le informazioni rilevanti (new).
Fare il backup dell'intero repository con TUTTE le informazioni è semplicemente copiare il file in giro. basta tenerlo nella cartella di sincronizzazione di dropbox ed il problema è risolto.
Potete estrarne l'ultima versione in una cartella (open), modificarla e, quando siete soddisfatti del risultato, inserirla come una versione successiva (commit).
Potete usare il controllo di versione per qualsiasi file text-based che volete, non soltanto il codice.
Ad esempio tenere la propria tesi ed il testo dei propri articoli sotto controllo di versione è generalmente una buona idea.
Ogni volta che vi allontanate dall'usare file di teste, perdete tutta la potenza di questi sistemi di controllo, ed è un vantaggio insostituibile!
import os
import contextlib
os.chdir(os.path.expanduser('~/lavoro/fossilexample'))
with contextlib.suppress(FileExistsError):
os.mkdir('../fossilexample/')
os.chdir('../fossilexample/')
print(os.getcwd())
with contextlib.suppress(FileNotFoundError):
os.remove('mytestrepo.fossil')
import shutil
shutil.rmtree('working_directory', ignore_errors=True)
print(os.listdir('.'))
!fossil init mytestrepo.fossil
%ls
%mkdir -p working_directory
%cd working_directory
%pwd
!fossil open ../mytestrepo.fossil
%%writefile test.txt
This is going to be my documentation
!fossil status
!fossil extra
!fossil add test.txt
!fossil status
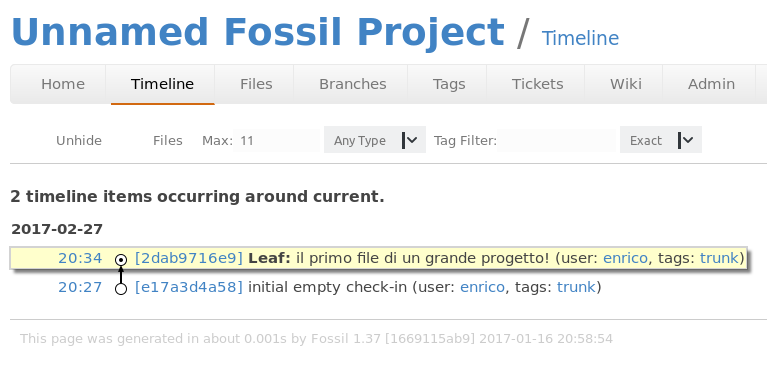
!fossil commit -m "il primo file di un grande progetto!"
!fossil status
a questo punto potete vedere cosa succere lanciando il comando
fossil uitimeline¶
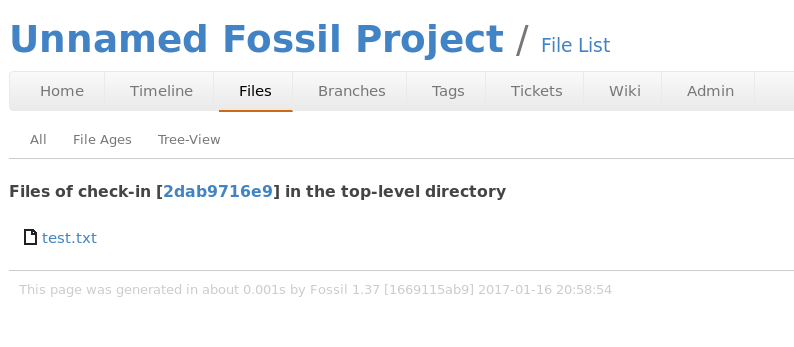
file list¶
%%writefile test.txt
This is going to be my documentation
I'm adding more lines: the more, the merrier!
!fossil status
!fossil diff test.txt
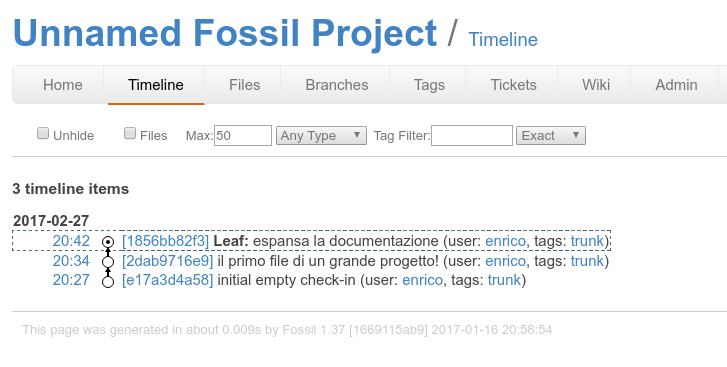
!fossil commit -m "espansa la documentazione"
nuova timeline¶
approfondimenti sull'edit¶
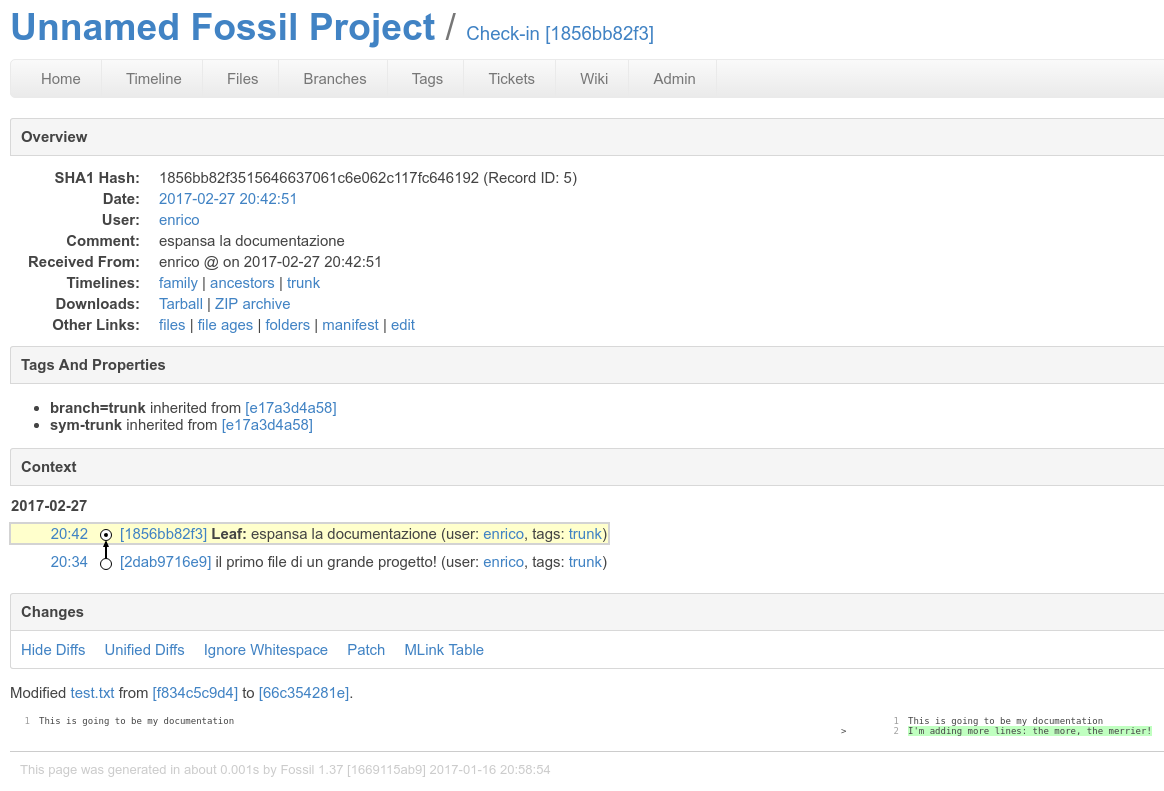
mi sono accorto di aver fatto un errore!
come posso rimediare?
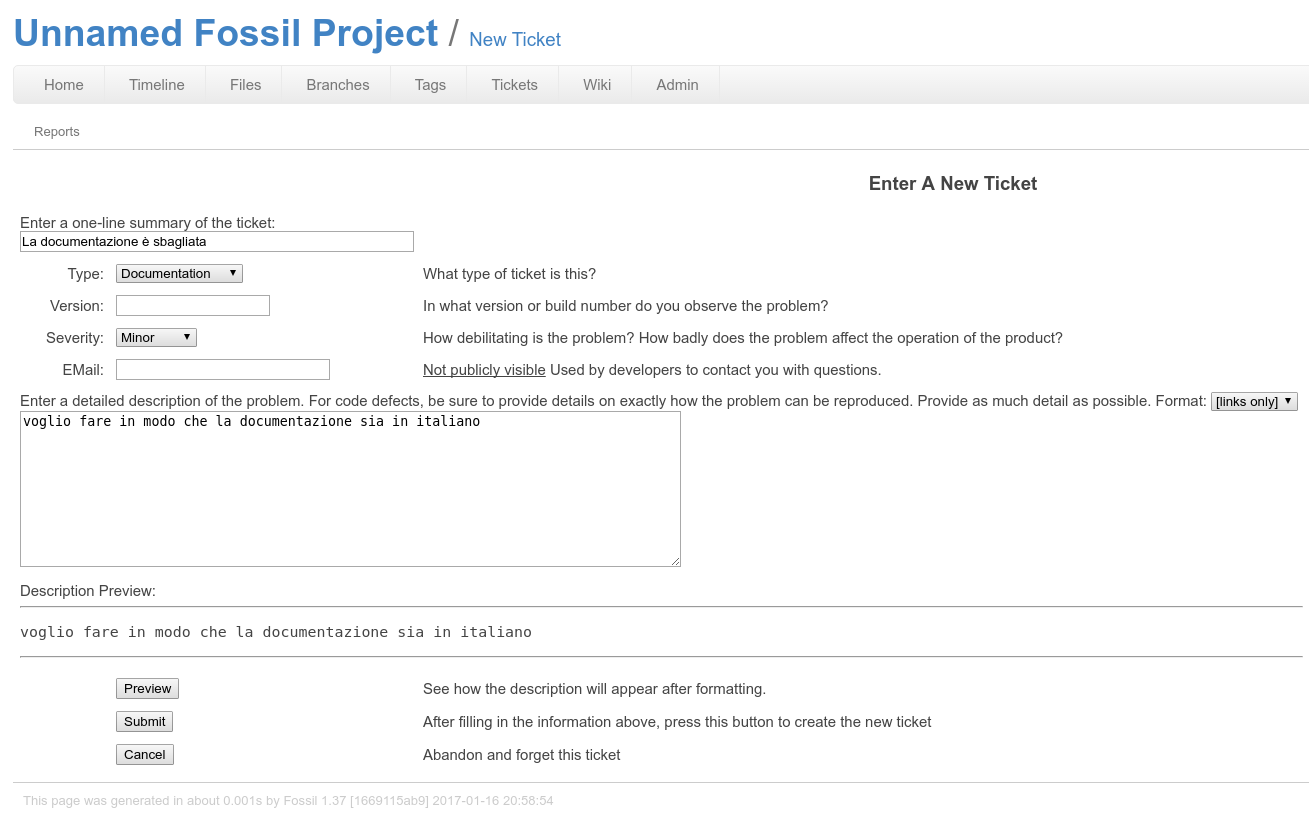
Per prima cosa, lascio traccia della decisione: apro un ticket.
preparazione del ticket¶
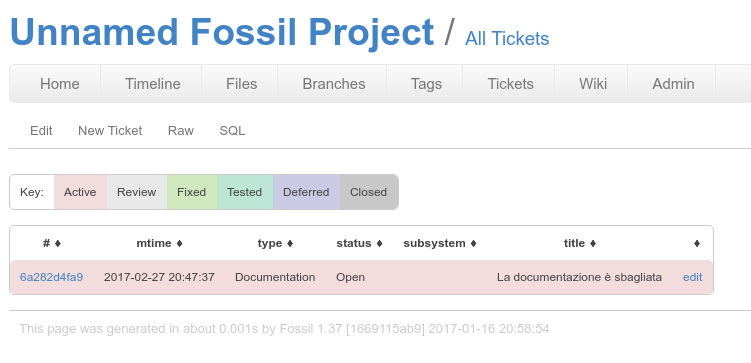
la lista dei ticket¶
!fossil help revert
!fossil revert -r 2dab9716e9 test.txt
!fossil status
!fossil diff test.txt
!fossil commit -m "riportato l'ordine nel repository!"
ora non mi rimane che chiudere il ticket e continuare il mio lavoro
branching¶
una funzionalità molto potente per il controllo di versione è la possibilità di fare branching.
Questo significa che nel mio database esistono nello stesso momento due versioni diverse dello stesso progetto, e posso passare da un all'altra senza problemi.
Un grosso vantaggio del modello di DVCS di fossil è che posso usare diverse cartelle per diversi branch, ed avere il tutto sincronizzato!
un caso tipico di branching¶
avete appena raggiunto un risultato pubblicabile con le vostre analisi, e volete prepararvi per pubblicarle.
Questo significa che non altererete più il codice in modo sostanziale (volete mantenere l'integrità dei risultati), ma magari aggiusterete i grafici ed i report.
Allo stesso momento, i vostri collaboratori vi chiedono di fare delle modifiche piuttosto importanti del codice. Come potete fare?
Usando due diverse branch siete in grado di dividere il lavoro senza fare confusione, ma mantenendo tutto sempre sotto controllo (e con la possibilità di far passare i risultati da un branch all'altro con revert).
!fossil help checkout
per comodità faremo il cambio di branch nella stessa directory, ma in generale creeremmo una seconda directory, apriremmo il repository e faremmo il checkout della versione che ci interessa.
In questo caso, ritorniamo allo stato iniziale del repository.
!fossil checkout e17a3d4a58
il repository è vuoto come l'abbiamo lasciato due commit fa.
ls
%%writefile test.txt
this is an alternative history
!fossil add test.txt
!fossil commit -m "nuova storia"
!fossil commit --allow-fork -m "nuova storia"
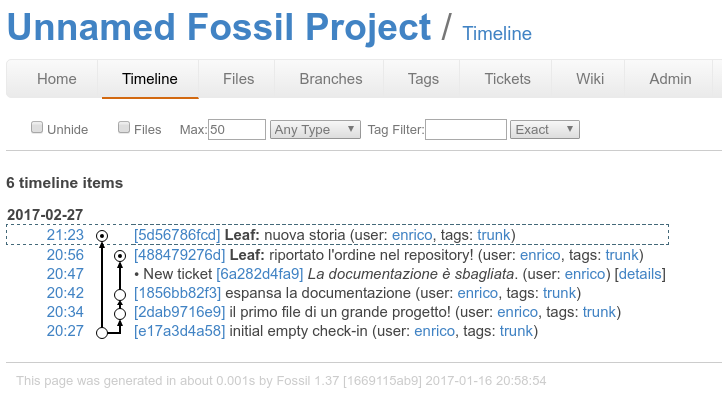
la nuova timeline¶
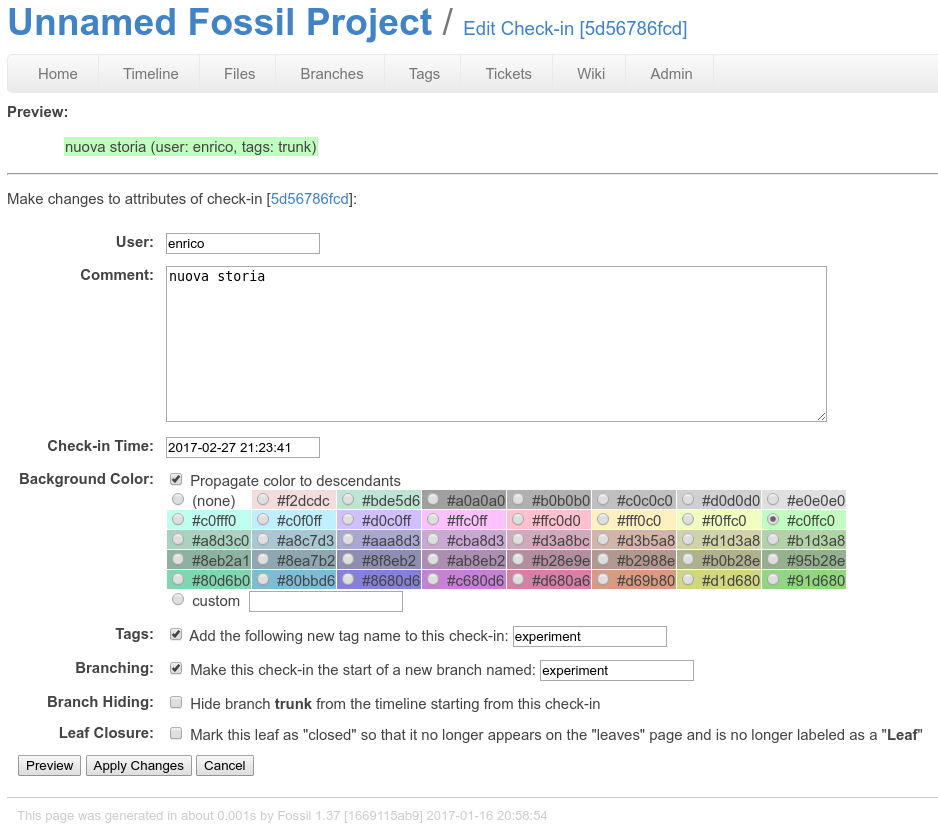
aggiusto le proprietà del nuovo branch¶
ecco come appare la mia timeline ora¶
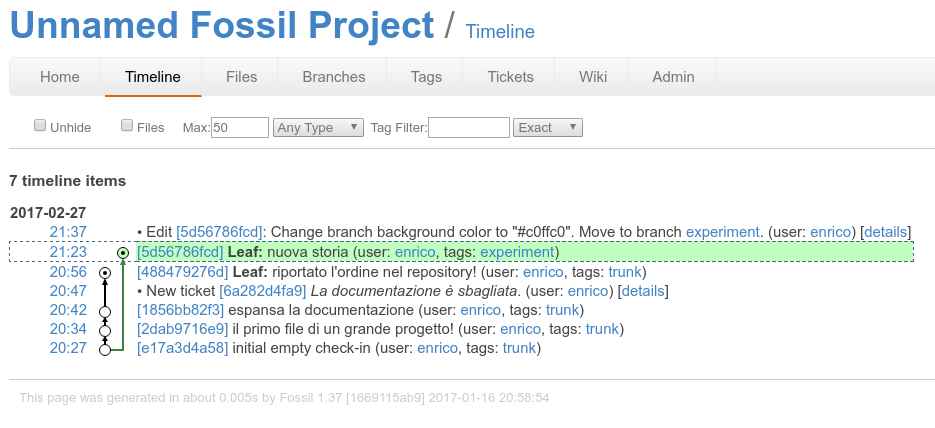
notate che viene registrato anche il cambiamento di nome del branch!
Un'altra operazione molto comune è rinominare o eliminare un file.
Un comportamento curioso di fossil è che registra il cambiamento ma non lo attua: dovete esplicitamente rinominare il file dalla linea di comando
!fossil mv test.txt test2.txt
!ls
!mv test.txt test2.txt
!fossil status
!fossil commit -m "cambiato il nome del file"
!rm test2.txt
!fossil rm test2.txt
%%writefile test3.txt
crazy experiments!
!fossil add test3.txt
!fossil commit -m "ultimo commit del branch sperimentale"
Ora, visto che ci piace renderci la vita complicata, vogliamo unire i due branch.
Questo può servire quando stiamo facendo delle modifiche sperimentali ad una parte della nostra analisi e non vogliamo includerlo fintanto che non siamo sicuri che stia funzionando correttamente.
Per fare questo dobbiamo usare il comando merge, ma prima dobbiamo metterci nella linea principale che vogliamo mantenere (visto che l'altra poi sparirà) con un checkout.
Questo risulta molto più facile se avete due cartelle separate. Se state usando la stessa, controllate due volte prima di fare il checkout!
!fossil checkout 488479276d
!fossil merge 47cc19ae1f --dry-run
!fossil merge 47cc19ae1f
!fossil status
!fossil commit -m "le due storie sono finalmente unite!"
la versione post-sperimentazione¶
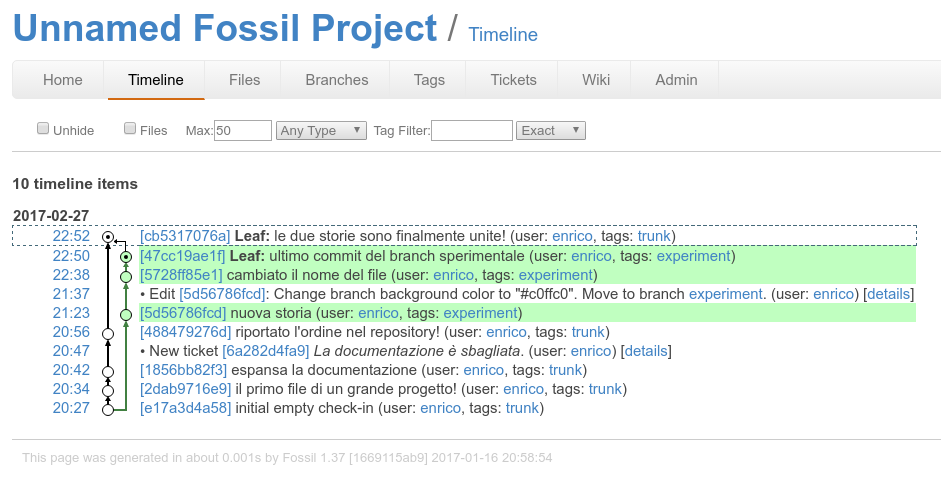
full disclosure¶
Il file che abbiamo modificato all'inizio, test.txt, dava problemi per il merge perchè creato indipendentemente nei due branch. L'unica soluzione che ho trovato è stata gestire il merge a mano, in pratica creare un nuovo file da zero ed eventualmente riempirlo con il contenuto del vecchio.